Synergize OCR Form Processing
The Synergize Form Processing module (originally introduced in Oct 2016 as Form Processing 1.9.0.32 or later) lets you process documents and forms to extract data and potentially save the original form into a Synergize repository. The module features an indexing solution for automated identification and data capture of forms and documents.
The goal of Form Processing is to reduce manual indexing. Form Processing is too often perceived as a magic bullet that can eliminate the need for employees to do any indexing work. Unfortunately, this results in unrealistic expectations, as optical character recognition (OCR) isn't flawless and reviewing and correcting misread documents is generally part of any solution. Form Processing includes an optional tool called Form Indexing that can efficiently do this review-and-correction step.
Synergize OCR Form Processing was enhanced with the following update for Synergize Release 16.5 in 2025; however, an associated known issue has also been detected:
-
Synergize OCR Form Processing now supports multiple users.
-
Known Issue: If two users save their changes at the same time, changes to a form processing template made by User B might override the changes made by User A.
With Form Processing, you can do the following:
-
Create data extraction plans, which group documents into standard entities that share common extraction fields.
-
Set up strategies to identify documents.
-
Extract information fields from documents.
-
Read machine and handwritten text, as well as visual form marks (check boxes, filling in bubbles).
-
Split arbitrary-sized batches into documents and process them individually.
-
Apply batch-level information to all documents processed from the batch.
-
Log in to Synergize to get field information (like names or data types).
-
Extract fields that do not correspond to Synergize fields.
-
Validate extracted field information with regular expressions and whether the data can be converted to a target data type (date, integer).
-
Handle unknown pages in a batch with a set of selectable strategies. Common unknown pages include cover pages, summary pages, and supporting documents, which are meant to be grouped with a particular document.
-
Use “Identification Tags” as hints to the identification engine. This can reduce the number of potential forms to match against or uniquely identify the form. This is used when you know something about the incoming batch ahead of time, such as all incoming files in one folder are from a certain distribution center and therefore can only be one of, say, five different forms.
-
Split documents in flexible ways. These can be based on combinations of split conditions, which can include splitting before or after when a given page is found, when a field on a page is present, its value changes, or it matches a regular expression. It can also decide when to split when a maximum number or minimum number of a given page type is reached.
-
Handle different sized images flexibly, including scans at different resolutions (in dots-per-inch or DPI) and in some cases changes in page dimensions (extra white space, frames, fax headers, and footers) by using scaling anchors. This is for extraction of data only, not for identification.
-
Perform color dropout, which can remove a given color (typically green) from the page, prior to trying to extract data. The common use case for this is to remove background lines and grids, but leave colored pen handwriting on a page, which gives significantly better results.
-
Test data extraction from the form processing designer, while creating the configuration.
-
Integrate with Synergize Process Server (SPS):
-
SPS actions can call out to the Form Processing service to process a single form or a batch of forms.
-
SPS actions can also interrogate the results, to use the extracted data, or convert the results into synergize documents, which can then be saved to a repository.
-
Optionally, an Indexing repository can be used in conjunction with SPS, in order to have automated concurrent processing of batches using input and output workflow queues.
-
-
Compensate for data being shifted during scanning or during the production of the document (for example, “subtotal” being shifted up or down the page depending on number of line items) by using what we call anchors.
-
Choose from different OCR engines for each field (actually on a per zone basis), with both free and paid options available.
-
Modify field information with regular expression transformations, character removal, and multi-line handling.
Form Processing is used in the following scenarios:
-
Identification of Documents (No Data Capture): This is a very common case, where indexing data is included with a set of related documents, usually in the filename, barcodes, or a metadata file, but the individual documents within the set are unknown. Form Processing is used to identify the individual pages (often "backup/supporting documents"), and when indexed as separate documents into Synergize, they are all saved with the same metadata.
-
Identification and Data Extraction of Single Pages: The documents are mostly single page forms, which usually eliminates the need to split them.
-
Identification and Data Extraction of Multipage Documents That Are in Their Own Files: This is a rarer use case, but whenever possible, it's advantages to have the documents pre-split, so that we don't need to have Form Processing split a document (which can fail, if pages of the document fail to read splitting values correctly). Sometimes, documents come pre-split, and sometimes, we can split a batch by barcode, before sending it to OCR.
-
Identification, Data Extraction, and Splitting of Documents That are in Batches: This is the most complex situation, but it is very common. Form Processing has a lot of options and strategies for splitting documents and how to handle unknown pages within a batch. Form Indexing is usually recommended for this scenario, for its ease of fixing documents that failed to split correctly.
To accomplish a review of the scanned documents and correct them, Form Processing is used in the following scenarios:
-
Use Synergize Workflow: This is the most common strategy for situations where Form Processing does not have to split documents. Documents that can't be identified or extracted are sent to a special workflow queue, where people manually index them. Optionally, identified documents can be sent there (or to a second workflow queue) to be reviewed as well.
-
Use a Lookup to Verify Data: The data that is extracted from a document is checked against a database, to see if it has been read correctly. An example would be if an order number (key field) and shipping weight (secondary field) are known ahead of time, and a key field (order number) is the only essential piece of information that the client needs to extract. Once both values are read, they are looked up against the database and if BOTH match to a single record (order), then this is seen as a successful read that doesn't need to be reviewed.
The key point here is that a secondary piece of information that is unique (or mostly unique) to the key field (order number) should be used, to verify that the the key field has been read correctly. Just verifying a key field, such as order number, is something that has been implemented several times, but it isn't enough to verify the data. Just because an order number exists in the database, doesn't mean that it's the one that's on the page. This is a rarely used strategy, but it is a great way to avoid manual review, if proper data is available.
-
Use Form Indexing: This is the preferred method, when dealing with Batches and splitting.
-
Don't Review (Unconditionally Accept): This is not recommended, but sometimes the information is not essential and the client doesn't mind that it's not always correct. This is most frequently used when assigning the document types of any supporting documents. The documents will be all together since the most of the metadata is the same, and if a supporting document is mistyped, it can be corrected on the fly.
The following pieces make up the Form Processing solution:
-
Synergize Process Server
-
Synergize Server
The Synergize OCR Form Processing Designer is a tool that helps you visually design how Form Processing will identify documents, what data to extract from the page, and how to map the information to Synergize documents. The Form Processing Designer lets you configure forms for identification and extraction, as well as configure the OCR Service, which does the actual processing.
Typical Designer Process:
To process a batch of forms, the following items are needed:
-
you need to set up each form from which you want to identify and extract information.
-
The system needs to know what text, in certain areas of the page, uniquely identifies a given page of the form (Anchors), as well as which areas of the form are read and extracted (Zones).
-
The system typically processes many of the same types of forms, perhaps from different vendors, but with the same (or most of the same) data to extract (Fields).
-
You group these forms together in what we call Extraction Plans, which the majority of the time map one to one with the document types in a Synergize Repository.
-
An Extraction Plan specifies how to extract and validate the Fields that the group of forms shares, while on individual pages, you specify how these Fields are mapped to regions on the page.
Designer User Interface:
The user interface for Form Processing Designer has three main sections:
-
List of extraction plans in a tree view (A)
-
Details about the extraction plan, form, page, anchor, or zone, including previews (B)
-
Menu on a toolbar for configuring, saving, and exiting (C)
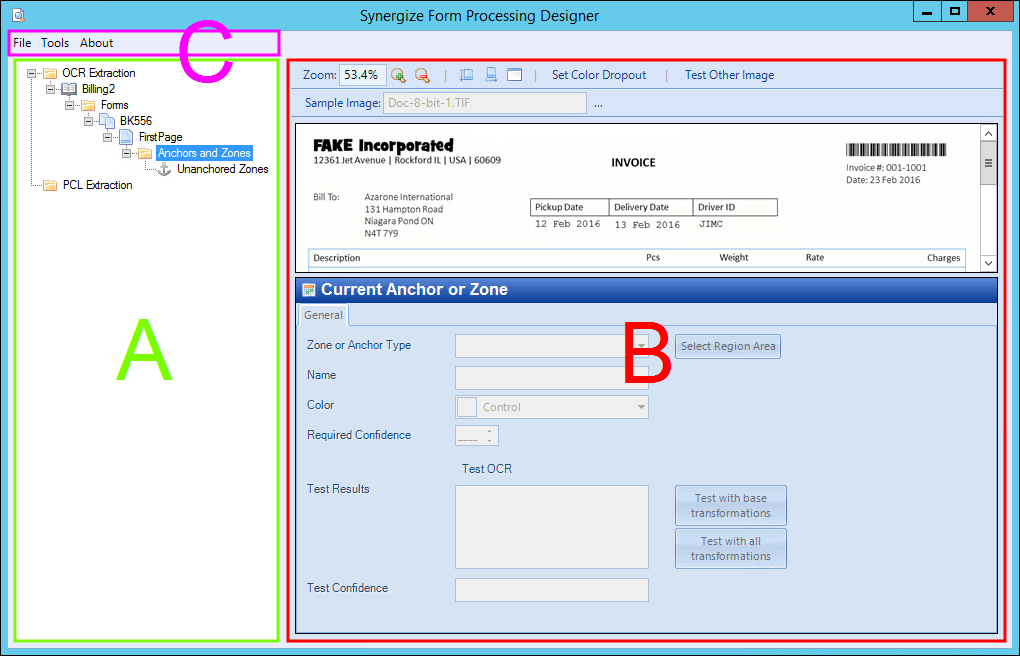
Extraction Plan List Hierarchy:
Generally, the extraction plans have a structured hierarchy. The subordinate nodes for each extraction plan are:
-
Forms: You can create multiple forms under any extraction plan. Each form is usually named for the company or customer that produced the form. A form contains pages.
-
Pages: You can create multiple pages for any form. For example, a Company X Invoice form may have a front page, detail pages, and a grand total summary/legal boilerplate page. A page contains anchors.
-
Anchors: You can create multiple anchors for any page. The more anchors you have, the more accurate the identification of the data will be. However, each new anchor increases processing time. An anchor contains zones.
-
Zones: You can create multiple zones for any anchor. Zones are the areas on the page from which you want to extract specific data.
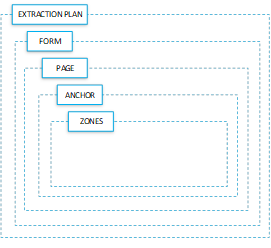
The node for each extraction plan can have multiple subordinate nodes. Each extraction plan is usually named for the document type from which they are designed to get data.
A collection of custom SPS actions for Form Processing and stock SPS actions allow you to process individual documents and batches, interact with the Indexing Repository, interrogate OCR results, and save data to a Synergize repository.
The Form Indexing application helps with reviewing and correcting documents that have been processed by Form Processing.
Form Processing can use several third-party optical character recognition (OCR) and optical mark recognition (OMR) engines when processing documents. OMR can detect data in check boxes, option buttons (formerly known as radio buttons), and other structures. Many third-party engines have been used over the years, but only the following are still supported:
1. Nicomsoft: A royalty-free OCR engine that is always installed with Form Processing. Because other SPS actions use Nicomsoft, it installs on its own, but it is required for Form Processing to run and the Form Processing install package will not install if it detects that Nicomsoft is not installed. Instead, the installation instructs you to install the Nicomsoft engine first.
2. Nuance: The OCR engine of choice at the moment. Its results have been drastically better in recent releases, thanks to their implementation of auto-zoning. If a client is getting poor results with an older install of Form Processing using Nuance, an upgrade is recommended.
3. Microdea: An proprietary Transflo engine that only does OMR. It was created when Nuance OMR results were deemed unacceptable.